之前由于学校强制的选修课,接触了尔雅通识课这个网络教学平台,然后由于需要提交作业以及线上作业,发现了“一个名叫尔雅通识课题库”的网站,而且声称开源,所以很有好感。
其实题库原理就是抓取尔雅通识课作业库的数据,然后汇总到自己的数据库里面提供查询功能。抓题没有研究过,因为这些课都是自动挂机挂完的(也用过秒过的脚本,但是怕服务器排查),加入验证码也是可以通过刷新页面过掉的。我只尝试过恶意请求作业题库,在请求作业的页面中确实可以请求其他的题目,但是答案无法获取,这里没有深究。
最近这个站点原来的地址被封了,作者开始想放弃了,然后在网站上声明准备放出网站源码和数据库。但是最近似乎想继续运营,于是换了新站,因为支付宝捐款链接确实能带来大量的收益。我以前闲着时候研究过的这个站的抓包取题,现在换服务器了当然失效了,但是现在有一点不爽,就是作者在主页醒目位置上贴出来GitHub链接(10个月没有push)败坏开源社区风气(或许可以说就不在开源社区)。而且升级版的网站改用Https传输,提高抓包难度,这个完全是掩耳盗铃表明自己不想开源。所以今天又来试着抓了一下包。
先来看看很久以前抓包弄出来的小库吧:
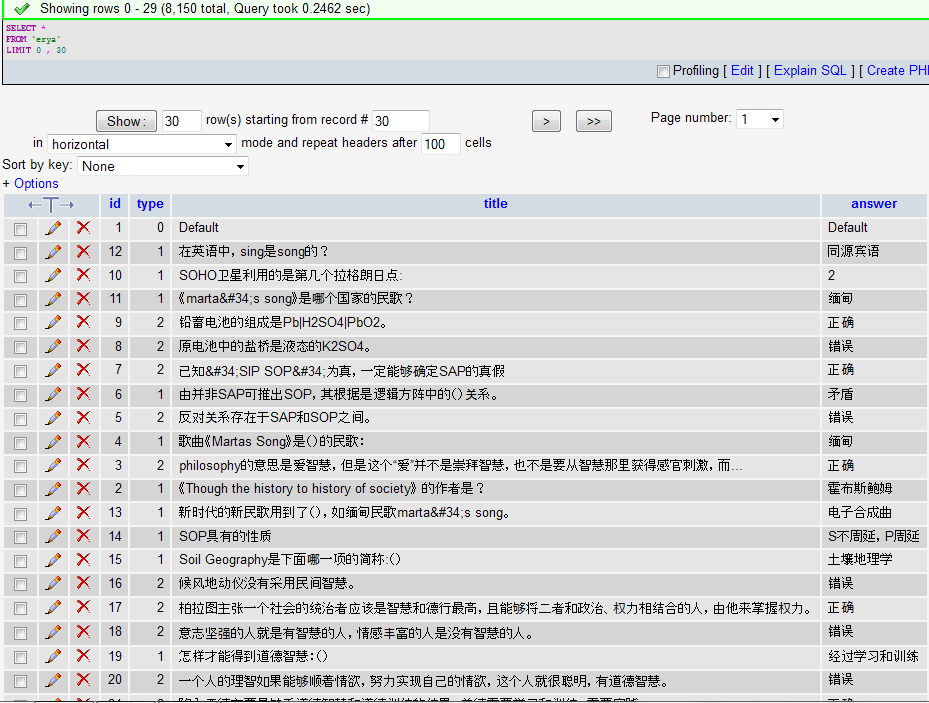
准备有空弄个汉语词典来抓取整个库。没事,可以通过多个云计算平台作为跳板的。
下面放出Python抓包的方法:
抓包其实很简单,你只要学习用python发送post数据包就可以了。然后要注意的是需要添加Referer为”https://www.erya.in/”,因为网站做了防止跨站请求的处理。
先从网站唯一的main.js看起:
function search() {
$.post('/', {'keyword' : $('#keyword').val()}, function(data) {
result = data['result']
$('#_').html('<ul>')
for (i = 0; i < result.length; ++i) {
title = result[i]['title']
type = result[i]['type']
answer = result[i]['answer']
ret = '<li><h5><small><strong>[' + type + ']</strong></small> ' +
title + '</h5></li>' + '<p class="answer">' + answer + '</p>'
$('#_').append(ret)
}
if (result.length == 0)
$('#_').append('<li><h5>未æœç´¢åˆ°ç›¸å…³ç”案</h5></li>')
$('#_').append('</ul>')
}).fail(function() {
$('#_').html('查询失败')
})
}
$("#search").click(search)
$("#keyword").keypress(function(event) {
if (event.keyCode == 13)
search()
})
$(function() {
$("#keyword").focus();
});
这个JS脚本作用是处理按钮的点击事件,点击之后向”/”发送post数据包,包的内容为keyword=xxx。一般情况下可以用HTTP Analyze进行抓包分析,并且直接可以模拟发包的,非常强大!
另外附赠老版本的post地址:”http://imhangerya0.duapp.com/”和”http://imhangerya1.duapp.com/”。
从前几行脚本能看出来返回的是json,然后我们就可以用Python来发送模拟包了:
server_url = "https://www.erya.in/";
submit = [('keyword',keyword[0])];
postData = urllib.urlencode(submit);
#return postData;
req = urllib2.Request(server_url, postData);
req.add_header('Referer', "https://www.erya.in/");
req.add_header('Content-Type',
"application/x-www-form-urlencoded; charset=UTF-8");
#req.add_header('Accept-Encoding', "gzip, deflate");
req.add_header('Connection', "Keep-Alive");
req.add_header('Cache-Control', "no-cache");
ret = "";
fd = urllib2.urlopen(req);
while 1:
data = fd.read(1024)
if not len(data):
break
ret += data;
j = json.loads(ret);
reload(sys)
sys.setdefaultencoding('utf8')
okkkk = u'';
for t in j[u'result']:
okkkk += u"[ Title ] " +t[u'title'] + u' | ' + t[u'type'] +
u'<br/>[ Answer ] '+ t[u'answer'] + u'<br/><br/>';
return (html_front + okkkk + html_back).encode('utf-8');
上面是处理函数的选段,包含需要的包即可运行,可以尝试在python脚本执行器里面执行。上面这一段的html_front和html_back都是返回的html段。(懂的人就会秒懂的)
处理完返回的就是这样:
[ Title ] 新约全书(New Testament)的包括:() | 单选
[ Answer ] 上述三项都对
[ Title ] protestantism是对哪个基督教分支的称呼 | 单选
[ Answer ] 新教
以上。
没想到网站还真封了啊。。。算了,网站也没机会抓了,我直接放出抓的约8000条题目给大家研究吧(约13%)。。。
我可不像那个某站长啊,我直接无偿放出来了,希望对大家有用的话能留下点评论,带来一点小小的流量就好。。。
数据库在此:erya.csv
题库绝对不全,因为我压根当时就没想去抓。